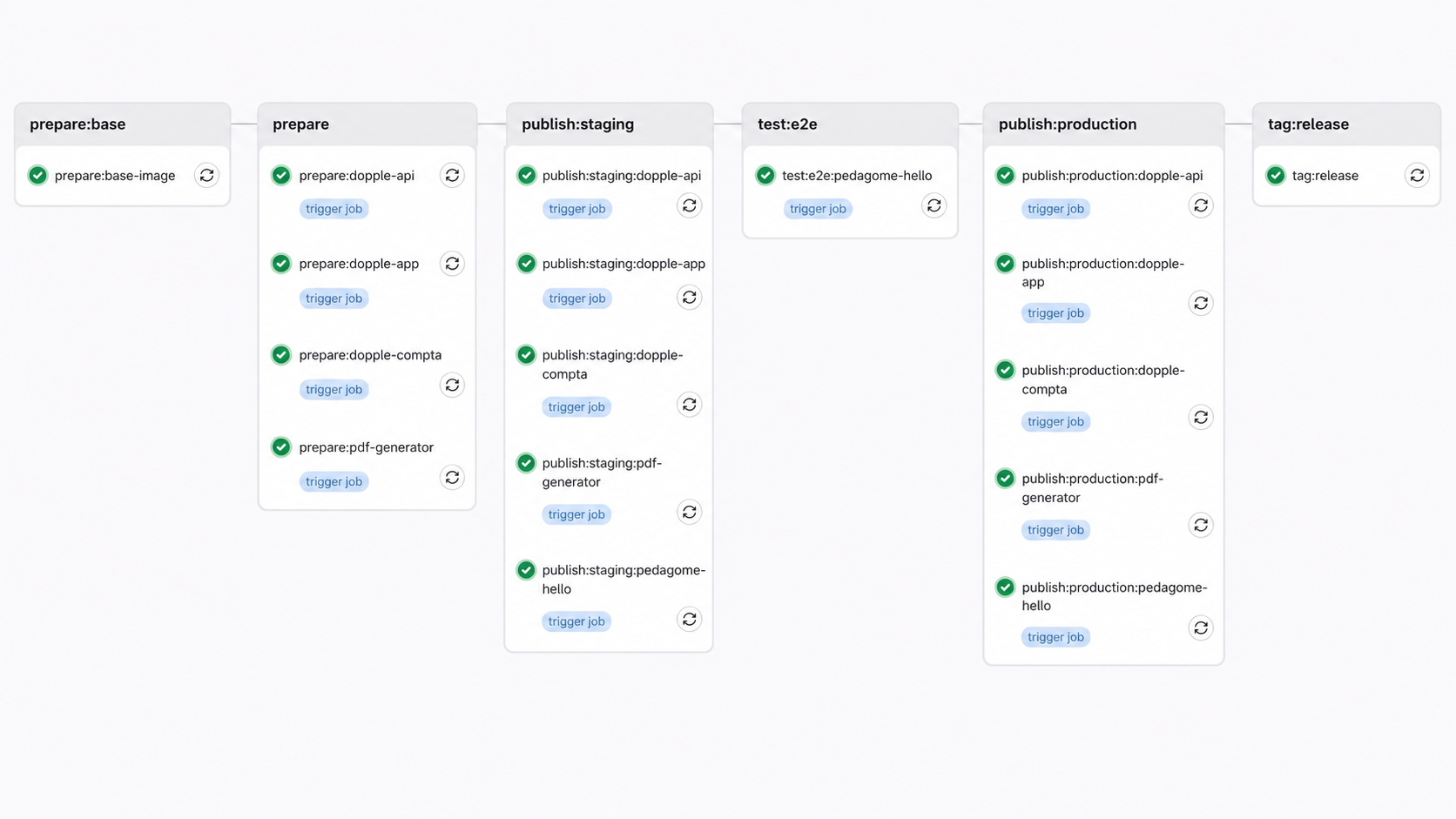
Monorepo Dopple
Contexte du projet
Pedagome est un organisme de cours particuliers à domicile situé à Metz. Pour suivre son activité, l’entreprise utilise Dopple, un système d’information interne qui centralise une partie du suivi commercial, administratif et opérationnel. Cet outil alimente aussi des parcours utilisés par des publics externes, comme les prospects, les clients ou les tuteurs.
Pendant mon alternance à l’ISCOD, entre 2024 et 2026, Dopple avait dépassé le stade d’une application unique. Le SI regroupait plusieurs apps et services : dashboard interne, espace tuteurs, site vitrine et génération de PDF.
Ces briques vivaient dans plusieurs dépôts distincts, avec des gestionnaires de paquets, des versions et des configurations qui évoluaient séparément. Cela restait acceptable tant que l’usage était surtout interne. Les erreurs pouvaient gêner l’équipe administrative, mais elles restaient rattrapables dans une certaine mesure.
Avec la multiplication des fonctionnalités exposées à des publics externes (clients, prospects ou tuteurs), ce fonctionnement n’était plus acceptable. Un problème sur un formulaire d’inscription, une candidature ou un parcours public pouvait directement bloquer un utilisateur. L’enjeu dépassait donc l’organisation du code : il fallait rendre l’ensemble plus fiable avant chaque mise en production.
Transition vers un monorepo
J’ai d’abord migré le projet vers un monorepo pnpm / Nx. L’objectif était d’avoir un seul espace de travail pour les différentes apps et packages, de mieux suivre les dépendances partagées et de cibler les builds selon les changements réellement apportés. Le monorepo regroupe aujourd’hui 6 applications et 6 packages.
J’ai aussi utilisé le système de catalogues pnpm pour mieux centraliser certaines versions de dépendances. Cela permet d’éviter que plusieurs projets censés fonctionner ensemble dérivent silencieusement vers des versions différentes.
Plusieurs packages partagés ont ensuite été structurés. Par exemple :
- shared-global, pour les constantes et fonctions utilitaires utilisées côté front comme côté back ;
- api-clients, pour les clients d’API générés à partir des spécifications OpenAPI ;
- shared-react, pour les utilitaires et composants communs aux applications React.
Cette organisation a permis de réduire les duplications et de limiter les écarts entre applications. Avant cette reprise, certaines fonctions utilitaires étaient copiées d’une interface à l’autre, et les contrats entre frontend et backend pouvaient évoluer dans des directions différentes. Quand un type, une constante ou un client d’API évolue, l’objectif est désormais que cette évolution soit portée par un package commun plutôt que recopiée manuellement à plusieurs endroits.
Accélérer les vérifications et les builds
J’ai utilisé Nx pour cibler les projets réellement affectés par une modification. Si un changement ne concerne qu’une application ou un package, il n’est pas nécessaire de relancer toutes les opérations sur l’ensemble du monorepo.
J’ai aussi mis en place des commandes run-many pour lancer le typecheck et le lint sur 100 % des projets et packages. L’intérêt est de conserver une vérification globale, tout en profitant du cache Nx : les packages inchangés ne sont pas systématiquement recheckés. En développement local, cela représente un gain important, car un contrôle complet pouvait prendre plusieurs minutes à chaque exécution.
Côté Docker, les images ont été découpées pour mieux profiter du cache des layers. L’image de base du monorepo contient les dépendances. Elle est invalidée seulement lorsque les fichiers qui pilotent l’installation changent : lockfile, package.json ou Dockerfile. Si seul le code applicatif change, les dépendances ne sont pas réinstallées.
J’ai aussi travaillé sur la persistance du cache Nx dans les pipelines GitLab. L’objectif était que les résultats déjà calculés puissent être réutilisés entre plusieurs exécutions et plusieurs stages, au lieu de repartir de zéro à chaque build. Sur un monorepo, ce point devient important : si une application ou un package n’a pas changé, il n’est pas utile de le recompiler ou de le revérifier systématiquement.
Mieux coordonner les déploiements
Les applications étaient déjà conteneurisées avec Docker, donc l’enjeu n’était pas de passer d’un déploiement manuel à un déploiement automatisé. Le vrai sujet était plutôt la coordination. Avant, les projets étaient séparés et il fallait gérer plusieurs merge requests, avec un risque d’écart entre ce qui était livré côté backend et côté frontend.
Ce point était sensible car le déploiement du backend déclenche les migrations de base de données. Si une migration échoue mais qu’un frontend dépendant de la nouvelle structure de données est quand même mis en production, le risque de bug est immédiat. Il fallait donc mieux coordonner les étapes : migrations, backend, puis les frontends.
J’ai mis en place un pipeline CI/CD GitLab avec des builds par application, le déploiement d’un environnement de staging, l’exécution de tests E2E Playwright, puis la publication en production après validation. L’objectif est que les éléments principaux soient testés ensemble avant d’être déployés en production.
Les tests Playwright couvrent surtout les flux critiques, notamment l’inscription des prospects et les candidatures. Ce sont des parcours importants, car une fois que l’équipe commerciale dispose des coordonnées de contact, une partie du processus reste rattrapable. En revanche, si l’inscription ou la candidature ne fonctionne pas, le taux de conversion est directement impacté.
Ces tests ont déjà permis de détecter des régressions, par exemple lorsqu’un champ avait été ajouté sur une entité de l’ORM sans que le script de migration correspondant ait été généré. Ce type d’erreur illustre bien l’intérêt du staging : simuler au plus près ce que sera l’environnement de production, pour bloquer le problème tant qu’il en est encore temps.
L’image Docker est construite sur un runner de développement, poussée dans le container registry de GitLab, puis téléchargée depuis le serveur de production. Cela évite de faire porter au serveur de production le coût des builds, qui peuvent être lourds en CPU et en RAM.
Pendant la transition, les mises en production ont aussi été planifiées avec prudence. Nous avons privilégié les déploiements en début de semaine, le matin, à des moments où l’affluence sur le site était plus faible. Cela laissait davantage de temps pour surveiller le comportement de l’application et corriger rapidement si un problème apparaissait.
Isoler le microservice PDF
La génération PDF a été un bon cas de découpage. La génération de factures, d’attestations fiscales ou d’autres documents avec Express, Puppeteer et React impose des dépendances particulières. L’image doit embarquer les éléments nécessaires à Puppeteer, ainsi que les polices utilisées par Pedagome.
Au départ, cette génération était intégrée au backend principal. Je l’ai isolée dans un conteneur séparé.
Avec des images plus petites et ciblées, la vitesse des déploiements s’est améliorée. Le backend principal n’a plus à embarquer des dépendances lourdes liées uniquement à la génération de documents. L’infrastructure est aussi plus cohérente : il sera possible de dupliquer certains containers si la charge d’un des 2 services devient trop importante.
Les interactions qui ont compté
Je gardais une forte autonomie sur les choix d’outillage et d’architecture, mais cette autonomie ne voulait pas dire que le sujet restait isolé. Les arbitrages se faisaient avec le CEO, notamment pour décider du temps à consacrer à l’industrialisation plutôt qu’à de nouvelles fonctionnalités visibles immédiatement.
L’équipe administrative et commerciale comptait aussi. Le SI était utilisé au quotidien, et une mise en production mal coordonnée pouvait bloquer une inscription, une candidature ou une opération interne. La stabilité des déploiements avait donc des conséquences concrètes sur l’activité.
L’accueil d’un stagiaire pendant dix semaines a aussi fait ressortir l’importance de l’environnement de développement. Le fait de devoir initier quelqu’un au projet, lui expliquer l’organisation du code et relire son travail rend vite visibles les zones floues : code dupliqué, conventions implicites, scripts peu lisibles ou dépendances dispersées. Cela a renforcé l’intérêt d’unifier le projet, de mieux structurer les packages partagés et de rendre les vérifications plus automatiques.
Résultats et perspectives
Le résultat le plus visible concerne les temps de build. Certaines opérations pouvaient prendre jusqu’à environ une heure dans les cas les plus lourds. Avec le ciblage Nx, les caches et le découpage Docker, les mêmes cycles se situent plutôt autour de dix à vingt minutes selon les changements concernés. Cela rend les corrections plus rapides à livrer et diminue la tentation de contourner les vérifications.
Les déploiements sont aussi devenus plus fréquents et moins risqués. Les correctifs peuvent être appliqués plus vite et les tests ont déjà bloqué des régressions qui auraient pu toucher directement ces formulaires.
L’environnement continue d’évoluer progressivement. Une dernière application n’a pas encore été intégrée au monorepo car elle est stable depuis plusieurs années et ne nécessite pas d’évolution importante à court terme. L’intégrer maintenant créerait surtout du travail de migration sans bénéfice immédiat. Elle sera reprise lorsque de véritables évolutions le justifieront.
L’opportunité d’évolution la plus significative concerne la préparation à une montée en charge horizontale. Pour l’instant, la charge réelle reste parfaitement supportable par l’infrastructure actuelle, mais préparer la configuration permettrait de réagir vite en cas de problème de performance : lancer plusieurs containers du même service en parallèle, répartir le trafic et garder des déploiements compatibles avec ce fonctionnement, par exemple avec Docker Swarm ou une solution similaire.
Ce que je retiens
Cette réalisation m’a surtout appris qu’il faut industrialiser sans surindustrialiser. Un pipeline ou un cache peut faire gagner beaucoup de temps une fois stabilisé, mais sa mise en place prend souvent plus de temps que prévu. Même en suivant la documentation, on rencontre des problèmes de compatibilité, des cas particuliers, des interactions imprévues entre configurations. Comme chaque essai peut prendre plusieurs minutes, le temps passé peut vite exploser.
Il faut donc savoir faire des compromis. Par exemple, je n’ai pas ajouté un environnement de test supplémentaire au pipeline : les tests s’exécutent directement sur l’environnement de staging. Pour une équipe plus grande ou un produit avec des enjeux plus critiques, ce choix serait discutable. Dans le contexte de Pedagome, il reste proportionné : les flux critiques sont testés, les mises en production sont planifiées avec prudence, et le niveau de complexité reste adapté aux moyens disponibles.